About
![]()
This book is continually revised and extended to teach the course Introduction to Data Science (using R, ADILT) at the University of Konstanz, most recently in 2026. It provides the curriculum and materials for the course, and is regularly updated and refined as data science evolves.
Contents and audience
This book contains materials needed to teach a variety of introductory courses on data science for undergraduate students of various disciplines.
Figure B.2 provides an overview of key concepts and topics addressed by this textbook (and some of the corresponding R packages):
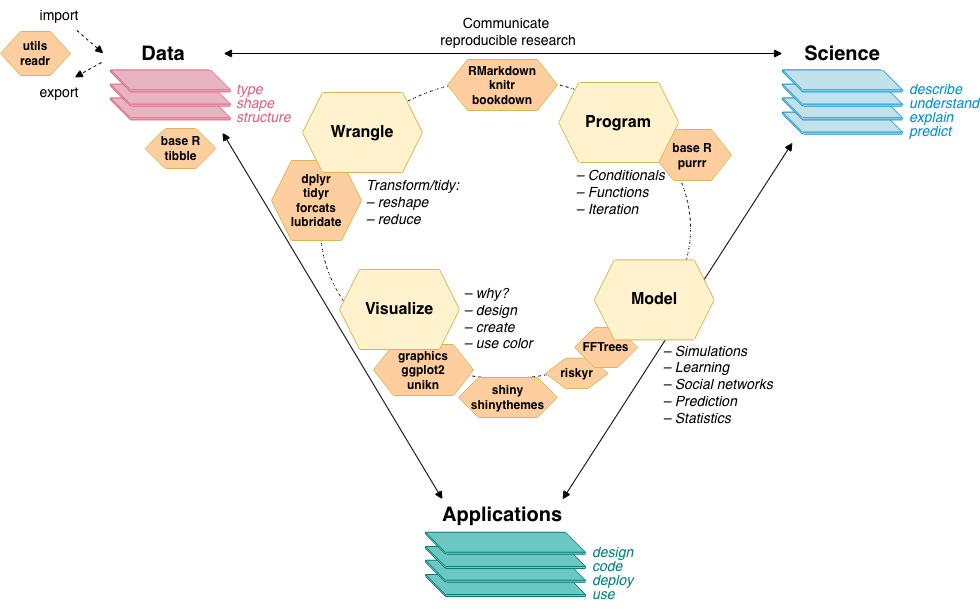
Figure B.2: Schematic overview of the key concepts, tasks, and topics addressed by the i2ds textbook (and corresponding R packages).
All materials and examples are designed to engage and motivate students from different fields to apply computational tools to solve challenging problems. Hopefully, students from all backgrounds and levels of experience will welcome the summaries of essential commands and find solving the exercises both enjoyable and enlightening.
Potential courses
The materials covered in the parts and chapters of this book can be flexibly arranged to support a range of courses and curricula. In our own teaching, they provide the basis for at least three distinct courses:
- Introduction to Data Science 1: Basics is an introductory course (at the undergraduate level) that essentially covers Part 1: Foundations through Part 4: Wrangling data. Depending on the time available, some chapters (e.g., in Part 3: Visualizing data) may be skipped or covered only selectively.
- Visualizing data is an intermediate course (at the undergraduate or graduate level) that gravitates around Part 3: Visualizing data. It also builds on the basics from Part 1: Foundations and Part 2: Programming, and may include selected later chapters (e.g., on generative art).
- Introduction to Data Science 2: Applications is an advanced course (for undergraduates with prior experience, or at the graduate level). It assumes familiarity with the topics and skills of Part 1: Foundations and Part 4: Wrangling data, and focuses on (selected chapters of) Part 6: Applications.
The auxiliary chapters on special data types (Part 5: Special data types) are largely self-contained and can be incorporated into any of these courses whenever the relevant data types — numbers and factors, text, or dates and times — are needed.
Beyond this book
This book is deliberately selective: As noted in our Welcome, we focus on rectangular data and on basic, transparent tools, rather than chasing the latest methods. Being explicit about what we leave out is part of being honest about our scope — and a map for readers who wish to go further.
Some topics lie intentionally beyond our scope:
Non-rectangular data. We work almost exclusively with data arranged in the rows and columns of tables. Richer structures — nested or hierarchical data, graphs and networks, images, or audio — call for representations and tools that we do not cover here.
Geo-spatial data. We do not address the representation and analysis of spatial data (maps, coordinates, map projections, or spatial joins). This is a rich and practically important area, well served by dedicated R packages (such as sf and terra) and by a substantial literature of its own.
Sophisticated machine learning. We introduce prediction and simple models, but stop well short of modern machine and deep learning (cross-validation pipelines, ensembles, or neural networks). Our aim is to build the intuitions that make such methods comprehensible — not to teach the methods themselves.
A note on statistics
A common surprise deserves comment: Many students arrive convinced that data wrangling and predictive modeling simply are statistics. In a sense, they are right — collecting, cleaning, wrangling, and visualizing data provide the unglamorous groundwork on which applied statistics rests. (Statistics is also a mathematical discipline in its own right — much of its theory requires little data wrangling at all.) Yet we deliberately stop short of inferential and advanced statistics: We do not teach hypothesis testing, confidence intervals, or the quantification of uncertainty, and we treat regression as a tool for prediction rather than for statistical inference.
This is a matter of sequencing, not neglect. Data literacy and reproducible practices precede and enable any serious use of statistics. A reader who can clean, reshape, visualize, and reason about data — and who appreciates the difference between predicting and explaining (Chapters 23 and 24) — is far better prepared for a statistics course than one who has memorized tests without ever having wrangled a messy dataset.
And science requires all of it: The practical craft of collecting, cleaning, and wrangling data is inseparable from the theoretical reasoning of statistics and mathematics. Genuine scientific work integrates the two, and the practical foundations built here are an indispensable part of that whole.
Where to go next
For readers ready to take the next steps, we recommend:
Statistical inference: Statistical Inference via Data Science: A ModernDive into R and the tidyverse (Ismay et al., 2025) takes a data-science-first path into inference with the tidyverse.
Statistical learning: An Introduction to Statistical Learning (James et al., 2021) is an accessible and widely used entry point to machine learning in R.
A broader tour: Modern Data Science with R (Baumer et al., 2021) covers many of these topics — databases, spatial data, and machine learning among them — in a single, R-based volume.
Spatial data: the sf and terra packages, and Geocomputation with R (Lovelace et al., 2025).
These directions extend, rather than replace, the foundations built here: The same emphasis on representations, tasks, and tools will serve you well wherever you go next.
Providing feedback
As this text is still being revised and data science is a dynamic field, it is likely that the current version contains some typos and mistakes.
Please email me (as h.neth at uni.kn) to report any errors, possible improvements, or any other feedback or observations that you are willing to share.
Citing and linking
Everyone likes being linked or cited. Feel free to adapt this book or parts of it to your own purposes, but please acknowledge its use in your own work.
![]()
- Neth, H. (2026). i2ds: Introduction to Data Science.
Social Psychology and Decision Sciences, University of Konstanz, Germany. Online textbook (version 0.6.04, June 22, 2026). Retrieved from https://hneth-i2ds.share.connect.posit.cloud/.
Online links
- As the structure of the book’s chapters and sections may change, links should only use the base URLs https://connect.posit.cloud/hneth/, or https://hneth-i2ds.share.connect.posit.cloud/.
Data science for psychologists (ds4psy)
The book has been started as a more detailed and extensive version of Data Science for Psychologists (Neth, 2026a) and uses the corresponding R package ds4psy (Neth, 2026b). The full reference of this companion book and package is:
![]()
- Neth, H. (2026). ds4psy: Data Science for Psychologists.
Social Psychology and Decision Sciences, University of Konstanz, Germany. Textbook and R package (version 1.3.0, April 22, 2026). Retrieved from https://hneth-ds4psy.share.connect.posit.cloud/.
https://doi.org/10.5281/zenodo.7229812
A BibTeX entry for LaTeX users is:
@Manual{,
title = {ds4psy: Data Science for Psychologists},
author = {Hansjörg Neth},
year = {2026},
organization = {Social Psychology and Decision Sciences, University of Konstanz},
address = {Konstanz, Germany},
note = {R package (version 1.3.0, April 22, 2026); Textbook at <https://hneth-ds4psy.share.connect.posit.cloud/>.},
url = {https://CRAN.R-project.org/package=ds4psy},
doi = {10.5281/zenodo.7229812},
}Online links
-
Ebooks are hosted at https://connect.posit.cloud/hneth/:
- Ebook Data Science for Psychologists (the ds4psy book, at https://hneth-ds4psy.share.connect.posit.cloud/)
- Ebook Introduction to Data Science (the i2ds book, at https://hneth-i2ds.share.connect.posit.cloud/)
As the structure of the book’s chapters and sections may change, links should only use the base URLs https://connect.posit.cloud/hneth/, https://hneth-i2ds.share.connect.posit.cloud/, or https://hneth-ds4psy.share.connect.posit.cloud/.
The URL of the R package ds4psy is https://CRAN.R-project.org/package=ds4psy.
License

Introduction to data science (i2ds) by Hansjörg Neth is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The HTML-version of this book uses Google Analytics to evaluate the popularity of its different chapters. The website does not collect any personal data of individual users.
Colophon
This book is still being written. Its current version was generated using R version 4.5.2 (2025-10-31) and the following packages:
- bardr (0.0.9), base (4.5.2), bookdown (0.47), bslib (0.11.0), car (3.1.5), carData (3.0.6), colorspace (2.1.2), datasauRus (0.1.9), datasets (4.5.2), dplyr (1.2.1), ds4psy (1.3.0.9003), FFTrees (2.1.0.9001), forcats (1.0.1), ggalluvial (0.12.6), ggcorrplot (0.1.4.1), ggdag (0.2.13), ggplot2 (4.0.3), ggridges (0.5.7), ggthemes (5.2.0), ggwordcloud (0.6.2), graphics (4.5.2), grDevices (4.5.2), grid (4.5.2), gridExtra (2.3), here (1.0.2), HistData (1.0.0), i2ds (0.0.0.9028), igraph (2.3.2), knitr (1.51), lubridate (1.9.5), magrittr (2.0.5), methods (4.5.2), modelr (0.1.11), palmerpenguins (0.1.1), patchwork (1.3.2), purrr (1.2.2), quartets (0.1.1), RColorBrewer (1.1.3), readr (2.2.0), riskyr (0.5.0.9004), rmarkdown (2.31), rvest (1.0.5), shiny (1.13.0), shinythemes (1.2.0), shinyWidgets (0.9.1), stats (4.5.2), stringr (1.6.0), tibble (3.3.1), tidyr (1.3.2), tidytext (0.4.3), tidyverse (2.0.0), unicol (0.4.0.9002), unikn (1.0.0.9005), utils (4.5.2).
Thanks to all package authors and the wonderful R community for making this book possible!